
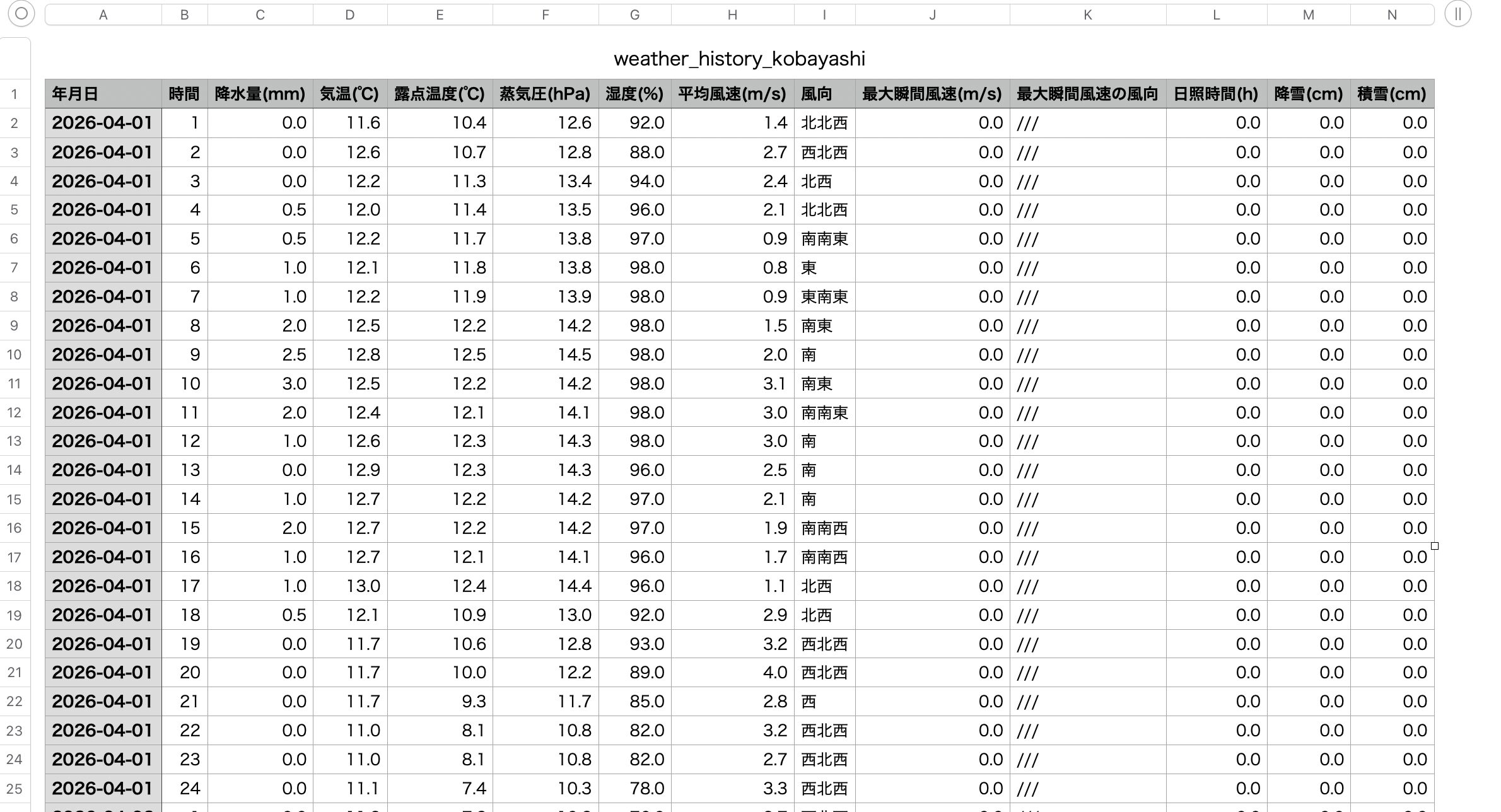
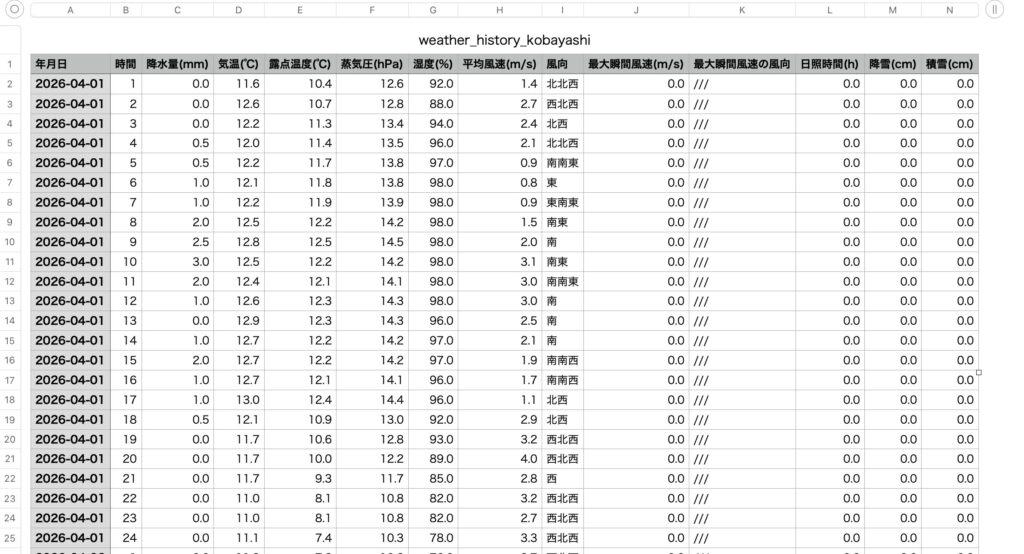
家庭菜園や地域の環境分析のために、気象庁のサイトに公開されている過去の観測データを自動で取得し、CSVファイルに蓄積し続ける仕組みを構築しました。
1. 観測地点の選定:なぜ「小林市」なのか
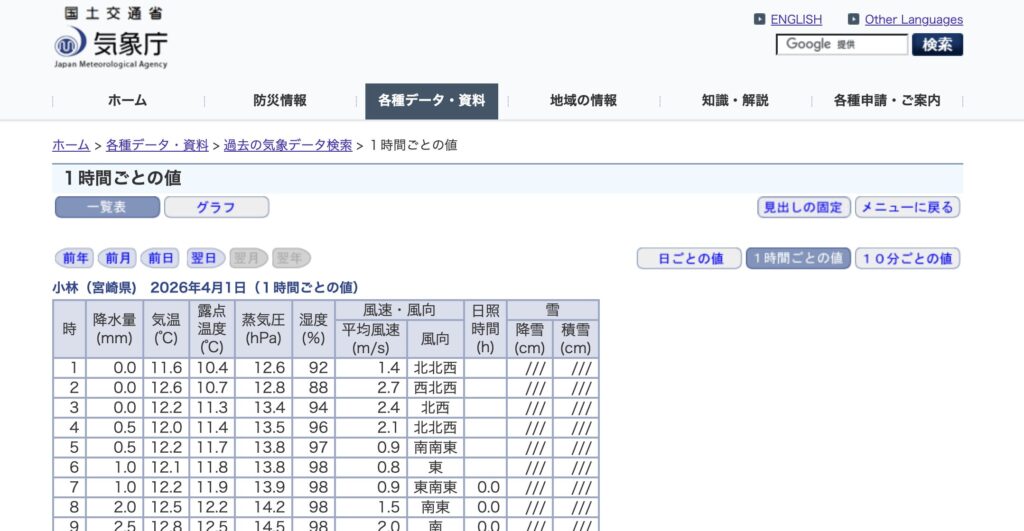
活動拠点である高原町にも、現地には気象観測用の設備が見受けられます。しかし、気象庁の「過去の気象データ検索」で詳細な数値を追おうとすると、高原町の地点はリストに出てこない、あるいは項目が限られていることがわかります。
これは、観測所によって「雨量しか測らない地点」や「防災専用の地点」など、役割が分かれているためです。高原町に近いエリアで、農業や生活に欠かせない気温・風速・日照時間などの多項目を安定して取得できる公式ポイントが「小林観測所」だったため、今回は小林市のデータを採用することにしました。
2. 最終版メインコード
このスクリプトは、既存のCSVファイルを確認し、不足している日付分(前回保存の翌日〜昨日まで)を自動で判別して追記します。
Python
# -*- coding: utf-8 -*-
import os
import datetime
import csv
import urllib.request
from bs4 import BeautifulSoup
import time
from datetime import timedelta
# --- 設定項目 ---
PREC_NO = 87 # 都道府県番号(87: 宮崎県)
BLOCK_NO = "0863" # 地点番号(0863: 小林市)
# 保存先設定(環境に合わせて書き換え)
OUTPUT_DIR = "/Users/ユーザー名/気象"
OUTPUT_FILE = os.path.join(OUTPUT_DIR, "weather_history_kobayashi.csv")
REQUEST_INTERVAL = 1.2 # サーバー負荷軽減のため
def str2float(text):
"""取得した文字データを数値に変換し、特殊記号をクリーニングする"""
if not text: return 0.0
text = text.replace(')', '').replace(']', '').replace('*', '').strip()
if text in ("--", "///", "×", "#", "", " "): return 0.0
try: return float(text)
except: return -9999.0
def scraping(date):
"""指定した日付のデータを気象庁HPから取得する"""
url = (f"https://www.data.jma.go.jp/stats/etrn/view/hourly_a1.php?"
f"prec_no={PREC_NO}&block_no={BLOCK_NO}&year={date.year}&month={date.month}&day={date.day}&view=")
try:
time.sleep(REQUEST_INTERVAL)
headers = {'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7)'}
req = urllib.request.Request(url, headers=headers)
with urllib.request.urlopen(req) as res:
soup = BeautifulSoup(res.read(), 'html.parser')
table = soup.find("table", {"class": "data2_s"})
if not table: return []
daily_data = []
rows = table.find_all('tr')
for tr in rows:
tds = tr.find_all('td')
if len(tds) < 1: continue
cols = [td.get_text().strip() for td in tds]
while len(cols) < 13: cols.append("")
row = [
date.strftime("%Y-%m-%d"),
cols[0], str2float(cols[1]), str2float(cols[2]),
str2float(cols[3]), str2float(cols[4]), str2float(cols[5]),
str2float(cols[6]), cols[7], str2float(cols[8]),
cols[9], str2float(cols[10]), str2float(cols[11]), str2float(cols[12])
]
daily_data.append(row)
return daily_data
except Exception as e:
print(f"❌ 取得失敗 {date}: {e}")
return []
def main():
if not os.path.exists(OUTPUT_DIR):
os.makedirs(OUTPUT_DIR)
yesterday = datetime.date.today() - timedelta(days=1)
start_date = datetime.date(2026, 4, 1) # 取得開始日
file_exists = os.path.exists(OUTPUT_FILE)
if file_exists:
with open(OUTPUT_FILE, 'r', encoding='utf-8-sig') as f:
lines = f.readlines()
if len(lines) > 1:
last_line = lines[-1].split(',')
start_date = datetime.datetime.strptime(last_line[0], "%Y-%m-%d").date() + timedelta(days=1)
if start_date > yesterday:
print("✅ データは最新です。")
return
headers = ["年月日", "時間", "降水量(mm)", "気温(℃)", "露点温度(℃)", "蒸気圧(hPa)", "湿度(%)", "平均風速(m/s)", "風向", "最大瞬間風速(m/s)", "最大瞬間風速の風向", "日照時間(h)", "降雪(cm)", "積雪(cm)"]
try:
with open(OUTPUT_FILE, 'a', newline='', encoding='utf-8-sig') as f:
writer = csv.writer(f)
if not file_exists: writer.writerow(headers)
current = start_date
while current <= yesterday:
print(f"📡 取得中: {current}")
data = scraping(current)
if data:
writer.writerows(data)
current += timedelta(days=1)
print(f"\n✨ 完了!保存先: {OUTPUT_FILE}")
except PermissionError:
print("⚠️ エラー: ファイルを閉じてから再実行してください。")
if __name__ == '__main__':
main()
3. 遭遇したエラーと解決法
ModuleNotFoundError: No module named ‘bs4’
実行時に「bs4(BeautifulSoup)がない」と怒られた場合は、以下のコマンドでライブラリをインストールします。
Bash
/usr/bin/python3 -m pip install beautifulsoup4
4. Macでの完全自動化 (cron)
毎日午前9時に自動で動かすための設定です。
- ターミナルで
crontab -eを実行。 - 以下を貼り付け。
Bash
0 9 * * * /usr/bin/python3 /Users/ユーザー名/kobayashi.py >> /Users/ユーザー名/気象/log.txt 2>&1
これで、PCを起動しているだけで毎日最新の気象データがCSVに追記され、その履歴が log.txt に残る仕組みが完成しました。
5. まとめ
今回の仕組みにより、高原町近郊の緻密な気象データが自動で蓄積されるようになりました。
- 手間ゼロ: 毎日サイトを見に行く必要がありません。
- 漏れゼロ: 数日PCを開かなくても、次回起動時に未取得分を自動補完します。
- 活用: 1年、2年とデータが貯まれば、自分の土地の気候変化を数値で振り返ることができる貴重な財産になります。


コメント